1
Want to hear something that blew my mind today? You know how when you come back to a Claude Code session after a few hours, the model feels noticeably dumber? Slower, clunkier, worse responses than… | Yoav Alon
www.linkedin.comWant to hear something that blew my mind today?
You know how when you come back to a Claude Code session after a few hours, the model feels noticeably dumber? Slower, clunkier, worse responses than you'd expect given where you left off?
I assumed this was about the KV cache. It's not. It's something more deliberate.
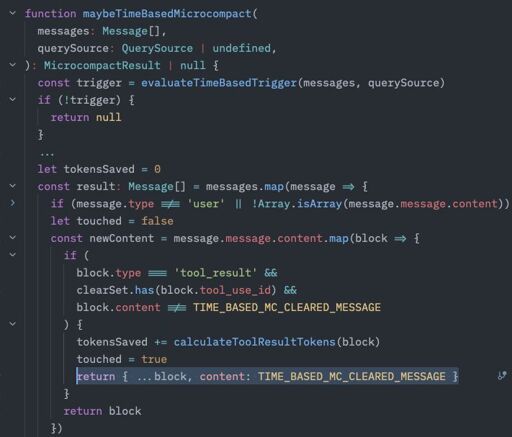
After digging into the Claude Code leaked source, here's what's actually happening.
Anthropic's prompt cache has a 1-hour TTL. When you're idle long enough for it to expire, Claude Code fires what it calls a time-based microcompact. It recognizes the cache is cold, and proactively strips out the content of every tool result in the conversation except the last 5. File reads, grep output, shell results, all replaced with [Old tool result content cleared].
Why? Cost. There's no point re-uploading tool results that won't benefit from the cache anymore. But the side effect is that the model literally can no longer see the actual data it worked with. Only the summaries it produced during compaction.
So you're not getting a dumber Claude. You're getting a Claude that's effectively starting a new conversation with a sketch of the old one.
It's a reasonable engineering tradeoff, but it explains the felt experience exactly
Originally posted by u/smulikHakipod on r/ClaudeCode
You must log in or # to comment.